
Challenges of (live) audio moderation
Moving to the higher level of communication

Thank you for taking the time to read this and I hope you walk away with a new perspective of how we use everyday technology. If you enjoyed this post, please do share with your network.

Content moderation is a little bit like insurance - you don’t really think or care about it, till something goes wrong and you need it. It doesn’t help, that content moderation is hard and subjective. I have written about the morality of taking something down in the past. But essentially, just because you think a post is bad, it doesn't necessarily mean that the post should be taken down, no matter how abhorrent you believe the post is. With Facebook and pretty much everyone else announcing audio products, there's a new dimension added to the unsolved problem of content moderation.
Audio content moderation is different. No one has managed to crack the secret formula to a the perfect content moderation with the current forms of media. Things always seem to go wrong one way or another. We've moved from moderating more simpler forms of content, such as text in my space profiles and tweets, to video and pictures, on YouTube and Instagram. But all of these mediums of content have two activities - they are processed on the backend of the platforms, and they are (in theory) stored indefinitely in the sense that you can retrospectively access content uploaded by users. These things don't happen so readily with live audio content. You can't pre-emptively predict what someone is going to say in a live scenario either, so how do you deal with bad actors?
Don't we already moderate content?
Content moderation is the act of judging whether something submitted to a platform adheres to the rules that the platform has set out. If it doesn't, the content is removed. Generally this is a good thing as it stops people posting things that should not be posted. Obviously, you are at the mercy of the 3 lizard people that run the internet, but generally they do a good job. Even platforms like Parler that claim they don't moderate content and allow 'free speech', still moderate content.
This moderation process can be done in a combination of automated filters, human and Artificial Intelligence (AI).
Automated Filter Moderation
Automated moderation is very simple version of artificial intelligence. Filters are setup, for example, the word 'drugs'. Then, whenever anyone uploads anything with the caption 'drugs' the post will be automatically either removed, or forwarded to a human. They are a good first line of defence.
This is more scalable than humans, but this is still limited, mainly to specific word. People also find ways to circumvent these types of filters, for example by writing a word substituting a letter with a character. Using the earlier example of 'drugs', someone could write 'd®ug$' and filter wouldn't catch it. One of the most vital issues, however, is that the filters don't have context.
Human Moderation
This is the most basic form of moderation. You see some content that you believe breaks the code of conduct for the platform you use. You report it. The report goes to a human who then has about 10 seconds to look at the horrific content and determine which intricate rule was broken, while also getting PTSD.
There are many problems with this system; the one businesses care about the most is the fact that it's not scalable. If you want more content being reviewed, all you can do is add more people into the equation, adding to the overall cost of the operation.
AI Moderation
This is the form that is the most widely used due to the sheer scale of the most popular social media sites. This uses various machine learning and AI techniques to identify and catch the bad content. This is the most versatile of the 3, as it can look through large amounts of text, images, video or audio, analyse and raise alerts accordingly (or even take down content). AI can also learn about context, meaning that it has a much larger scope of understanding of whether a post is compliant or not. This can save humans a significant amount trauma.
However, like with everything, it has its flaws. It's difficult to know why AI made a specific decision and it can be easily influenced to be terrible. AI is great for pre-moderation similar to automated filters, but for fringe cases you will always need a human judging the nature of the content.
With the combination of the 3, we have a fairly robust content moderation system in place, although it's something we are still working on. A combination of these will have to be used for audio moderation - however, this alone won’t be enough.
High-context and Low-context communication
In anthropology, there is a concept called 'High-context and Low-context communication'. High-context communication or culture is a group of people who communicate beyond verbally explicit communications to convey their messaging requiring the receiver to read between the lines, whereas Low-context communication is the opposite. Low-context communication is direct, explicit and precise. Different cultures and social media forms fall in different parts of the scale.

If you offer some food to someone in Germany, and they don't want it, they are likely to say 'no' or 'no thank you'. This is not considered rude. They are explicitly expressing how they feel about the situation. However in Japan, they are more likely to say something like "It is under consideration" implying that they do not want whatever you are offering. In my mother-tongue Bangla, it is incredibly rude to say 'no' or 'no thank you' in this situation and you would say something along the lines of "not at the moment" or "maybe later" (if you refuse the food at all in the first place, which is a big no-no. You are more likely to accept a very small amount and then refuse further offerings). They are requiring you to read between the lines.
This isn't just for cultures either. In the workplace, the sales people are high-context communication whereas with IT it is low-context. When you have an IT issue, you have to spell out the problem in literal terms otherwise you can not get your point across. Sales people need to read subliminal cues, such as body language and facial expressions, to understand how the customer is feeling. These are two vastly different ways of communicating, and they can not be switched. A literal sales man would be awful at selling and an IT technician will not be able to get to the root of your problem without you being literal in your problem (which at times can be very frustrating).
So what does this have to do with audio? Well, the majority of the internet is 'low-context' communication. With text, what you see is what you get. The expression of your ideas are explicit. The internet thrives on low-context communication as it allows anyone to get involved. Majority of the internet is also from the US and Europe, where low-context communication is the dominant form. But with things like pictures and videos, and especially audio, the communication context is higher, with audio I’d argue being the highest of them all.
Let's look at this at an example:
Say you have the statement 'I love chocolate' as text. This statement is clear and explicit and anyone can read it and understand the meaning.
If you upload a picture with you pulling a disgusted face at the sight of chocolate, the user can clearly see in the picture that the image of chocolate is giving you a negative reaction, so you probably don't like chocolate.
If you upload a video without sound of you looking at some chocolate and then scrunch up your face in disgust, you probably don't like chocolate. The level of abstraction is similar to the pictures, and you are requiring to use the context of the video to understand that.
If you upload an audio clip of you saying 'I love chocolate' (I understand the challenge of trying to express this high-context situation in a medium of low-context), you need to understand the tone and rhythm. Was it a short 'I love chocolate'? Or was it a 'I loooooovvveeee chocolate'? Is that expressing extreme positivity, or is it sarcasm? Tone, rhythm, accent and inflexion play a large role in determining the true meaning behind this message. This is high-context communication.
We can't use low-context tools for high-context content
Audio carries significantly more information than text on a communication level as well as raw data.
Text is encodable - the information can be broken down so that the computer easily read the information. Video and images are slightly more awkward, however we have found ways to encode and teach AI to read images and videos easily. There isn’t an easy direct way to analyse the hard core audio without transcribing first.
Text requires much less memory to store and is more structured than audio (images and video use large amounts of memory though). Storing all the audio from every live audio space will be very expensive, so you’ll only want to hold on to audio for exactly as long as you need to.
It's much easier to use AI to analyse a huge amount of text. This is the same with video and images. AI is sophisticated enough to go through the images itself without an intermediary step. With audio (at the moment), what happens is that the audio is transcribed into text and then the text is analysed for bad content, assuming that the audio is even correctly transcribed. Tone, rhythm and accents are lost, which are vital bits of information in an audio snippet.
Text is quicker to scan. With audio, you are time bound. If someone says there is bad content from around 10 to 15 mins in, you have to listen to the full 5 mins to hear the whole section and determine if it is bad or not.
Now imagine the challenge with live audio. You can't do majority of the content moderation techniques outlined above, as it's real time. We don't have the technology yet to analyse all this information when it happens and take action. When you tweet something, it's there all the time, and Twitter can retroactively go and fix it. With live audio, that is not the case at all. It's said and then it's done.
For live audio rooms, the reports would be second hand reports. Someone in the room will have to report the problem, and the moderators will have to trust the second hand report and only the other people in their room can verify the validity. That's also assuming that the moderator understands the context of the communication.
So what can we do?
So audio has a lot more nuance than traditional text based media, so how do we go about moderating this?
Well the best way to moderate audio at the moment is to use community moderators. Reddit is a great example of how effective this can be.
Reddit is a social media platform with a bunch of subcommunities. For example, if you really like chickens, there is a subreddit (subcommunity) dedicated to chickens. There's a subreddit for pretty much everything. Each subreddit has it's own culture and norms of communicating. Moderating all of that will be tough. So Reddit sets some basic ground rules and tells people to nominate themselves within the community to add further rules to build off of that and enforce them.
For example, Reddit can say that you are not allowed to talk about killing someone on Reddit. The chicken community might add that you can't talking about killing chickens either. But if you go to a meat eating subreddit, that rule won't stand. So it's up to the chicken subreddit moderators to enforce that one rule within their own community. They understand the context and nuances in their own community, so are more suited to make those decisions. The moderators are also generally voted in by the wider community. This is how audio should be moderated at this stage.
This may sound like the worst idea, but it's overall worked for Reddit. Sure, there are some bad actors, but in the grand scheme of things, people don't like talking about toxic stuff (unless of course, your visibility is dependant on it).
Intels N-Word filter
The closest thing we have to real time moderation/censorship is Intel’s 'Bleep' tool. It's aimed at tackling the toxic communication that takes place in gaming, but I can see this being extended to other communities. The Bleep tool analyses audio in real time and can censor specific words from the conversation in real time. The way you set this up is that you determine how much censorship you want with some sliders with a specific toggle for the N-word.
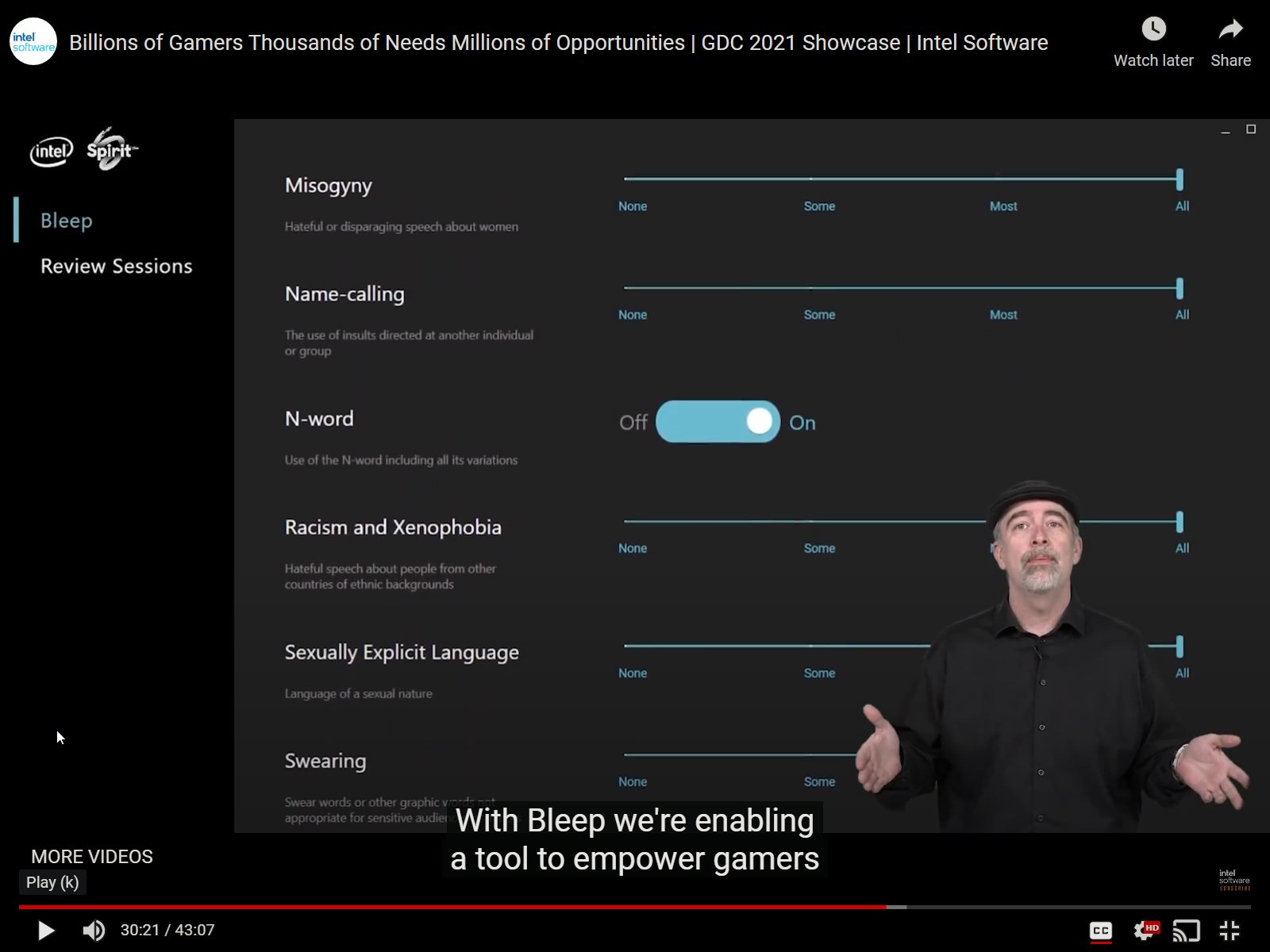
This was laughed at everywhere on social media, as in using low-context communication to convey high-context communication, it looked a bit bizarre. Surely misogynistic commentary should be a binary switch, no?
While I agree with the commentary on Twitter, I think Intel has called the sliders wrong. Intel clarified it was the sensitivity of the tool that is being determined here, not how misogynistic the commentary is. The tool is powered by AI trying to understand high-context communication, so it may mistake some parts of conversation to be misogynistic when it isn't. This error margin is being relaxed with the sliders, meaning that it will be less aggressive with the bleeping. You might put it to the top and bleep out everyone's conversation, so you would want a sensitivity meter so you can adjust to your needs. It doesn't mean that you want to be more misogynistic. With the N-Word, it's a binary state. Either you're hearing it or you're not. That's why it's easier to toggle it.
These 2 methods are our best bet at the moment. A conversation to a smaller community of people may be appropriate but out of the context of the community, it might sound inappropriate (for example, imagine seeing this post without the context of Formula 1). So you need the community to self moderate. Now obviously, a group of people with racist ideologies will not self moderate racism, which is why you would still need some base ground rules for each audio community to follow. But beyond that, the most effective way as of this moment to moderate audio and live audio is to have a Reddit-like community moderation system, until we have a real time tool that can analyse audio, along with the tone, rhythm, accents and inflexions, to fully understand the context of the communication, and determine what is appropriate and what is not.
Until then, I'll just have to push my misogynistic and racism filter to 'All'.
If you have a better idea than I do, if I’ve missed out anything or you think I am talking absolute rubbish, regardless if it’s positive or negative feedback, feel free to reach out either by commenting on the post, or by emailing me on tanvirtalks@substack.com
If you enjoyed this post, subscribe to Tanvir Talks, where I publish a podcast twice a month and a newsletter once a month breaking down the big questions asked in tech into digestible chunks for you to consume, the average consumer.